So, this article is going to be a little different. There will be very little code, a small discussion on site scrapping. The goal is to present an interesting problem, some data and maybe some conclusions about the data.
Recently I ran across a discussion on Twitter about building a Scrabble board using the letters in the Macedonian Language. Scrabble is a basically a word game, where points are won by placing tiles with letters on them, on a game board of 15x15 tiles. The goal is for the tiles to make actual existing words. The points awarded for a word depend on the letters of the word; more frequent letters award less points and less frequent, more. I won’t go into the details of the rules or how it’s played.

The interesting thing here is that Scrabble boards/games come with 100 tiles, so that is ~100 letters, as usually there are 2 blank tiles to consider when building a Macedonian version Scrabble. The real problem starts when you think about how to distribute these 98 remaining tiles. Which letter is going to be most represented to which letter the least.
English Scrabble
The current distribution of letters and scores in the English version is given in the image bellow taken from this Wikipedia article.
This distribution of counts and scores, as mentioned in the article, has had a tendency of changing through history. The thing that stands out is that the initial distribution was derived from letter frequencies in the text in the front page of the New York Times.
The original designer, Alfred Mosher Butts, manually counted the letter appearances in the magazine and from those numbers decided on the initial distribution of tiles.
Building a Dictionary and Frequency Count
I got very interested in the Scrabble subject when I saw that there was no easily findable equivalent data about letter frequencies in Macedonian. Something akin to the English letter frequencies seen here.
The frequencies can be used as a starting point to build the letter distributions for a Scrabble tile set.
So! How to build these frequencies? Well, recently I’ve been working on site scraping and was very excited to get to do something along those lines to collect a robust enough collection of words on which I would then run a count for each letter. I would then have a total letter count in all the words and individual letter count which is all that is needed to calculate a percentage.
Dictionary Scrapper and Parser
I implemented a little scrapper using simple WebRequests in C# and ran it against an online Macedonian dictionary. I was very lucky that the returned raw HTML contained all the necessary information to get both the words and the parameters for the paging structure used in the dictionary site. The approach was, once all the words on a given page were scrapped I built the URL for the next page and continued the process for all letters.
The parsing code was straightforward using the HtmlAgilityPack and xPath to get the nodes containing words. One easy way to determine the xPath string, if like me you have not have had the chance to get into xPath in detail, is to use the Chrome Dev tools and copy the xPath for the given node, and then with small modifications you can arrive to strings that select multiple nodes.
For example given the HTML in the image below the copied xPath is
- //*[@id=”lexems”]/select/option[8]
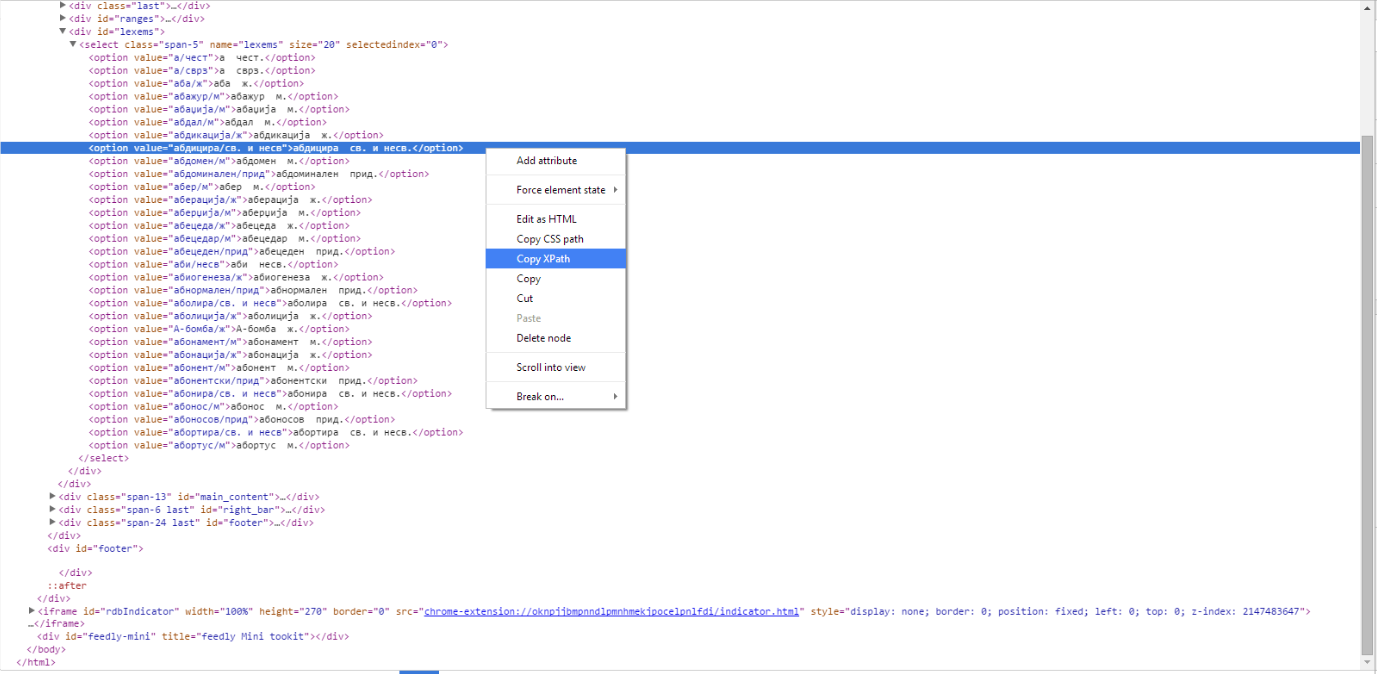
If we remove the node order “[8]” parameter we can get all the option nodes, and from there on all the words for the given page.
IMPORTANT! One thing that can cause trouble here is that the HTML seen in the developer tool window might be different than the HTML that is returned when making requests using a C# WebRequest. The thing is, the browser loads and executes JavaScript that might modify the DOM from a starting HTML structure to what we see in the developer tools. Using a WebRequest we get this original unmodified HTML.
The original HTML for the page and the words specifically can be seen bellow:

So we can modify the xPath further to work with this unmodified (no JavaScript ran) HTML to get
- ”//*[@id=’lexems’]/a”
Which selects all the anchor links.
Using HTML Agility Pack we load the raw HTML, select the anchor nodes using the xPath and then can easily get the anchor text. Using simple string parsing we can get the word and the word type.
I won’t cover the paging details but it boils down to figuring out how the page handles getting next word sets and what elements in the raw HMTL can be used to create the new request for the new set. For the given online dictionary I was able to page by iterating over all the Macedonian lowercase letters and then site specific word ranges for each letter.
Saving the Dictionary and Scrapping Considerations
One thing I wanted to do was run the scrapper as little as possible and bring the request count down as much as possible. I ran initial single tests for only one letter to make sure the paging for individual letters worked, as I was sure the letter (switching from а to б) paging itself was going to work.
After all words for each letter were parsed I saved them in a database for latter processing. The database was simple with one table containing columns for id, word and word type.
I setup delays between each request made to the site. Mainly because I thought it would reduce the load on the site (not crash it – even though I don’t know if its possible to do so with the requests I was making) and possibly prevent any measures they might have against scrapping.
It took I think about an hour to an hour and a half with the delays I setup to get the total ~54.000 words. The counts for words can be seen in the table bellow:
| First Letter | Word Count |
|---|---|
| п | 7889 |
| с | 6886 |
| р | 4212 |
| к | 3545 |
| н | 3192 |
| з | 2409 |
| д | 2406 |
| о | 2337 |
| и | 2202 |
| м | 2028 |
| б | 1982 |
| т | 1956 |
| в | 1748 |
| а | 1276 |
| у | 1151 |
| г | 1133 |
| ш | 1068 |
| л | 1002 |
| ф | 912 |
| ч | 817 |
| е | 817 |
| ц | 657 |
| х | 530 |
| ж | 412 |
| ј | 366 |
| џ | 184 |
| ќ | 134 |
| ѓ | 91 |
| ѕ | 78 |
| љ | 30 |
| њ | 3 |
Calculating the Frequencies Once the words were in the database it was
simple to calculate the frequencies for each letter based on the number of occurrences of each letter and the total letters.
The code for the method is given bellow:
public FrequencyResult GetPercentageEachLetter()
{
var result = new FrequencyResult();
// get all the words from the context
var WRDS = _context.WordDefinitions.ToList();
var counterDictionary = new Dictionary<char, int>();
var totalProcessedLetters = 0;
var totalProcessedWords = 0;
foreach (var dbWord in WRDS)
{
// dbWord stores both Word and Definition.
// we are working/counting letters in the word
var word = dbWord.Word;
totalProcessedWords++;
// Start letter counting for the word
foreach (var letter in word)
{
// because the letter list is all lowercase
var lcl = char.ToLower(letter);
// Only count the letter if the character is in the letter list of
// Macedonian letters, so if its not there move on to the next letter
if (!Letters.LetterList.Contains(lcl))
{
continue;
}
// increase the count of processed letters
totalProcessedLetters++;
// if the dictionary used to count the occurences of the letter
// does not contain an entry for the letter create it at 0
if (!counterDictionary.ContainsKey(lcl))
{
counterDictionary.Add(lcl, 0);
}
// increment the dic. count for the letter
counterDictionary[lcl]++;
}
}
// set the result objects total processed words and letters
result.TotalProcessedLetters = totalProcessedLetters;
result.TotalProcessedWords = totalProcessedWords;
// create the data structures for calcualting the frequencies for each letter count
var totalCountPerLetterList = counterDictionary.ToList();
var frequencyDictionary = new Dictionary<char, double>();
// Calcualte each frequency for each letter based on the letter count
// and the total letter count
foreach (var countPerLetter in totalCountPerLetterList)
{
var numberOfOccurencesForLetter = countPerLetter.Value;
var percentageOfLetterInAllLetters = (100.0 * numberOfOccurencesForLetter) / totalProcessedLetters;
frequencyDictionary.Add(countPerLetter.Key, percentageOfLetterInAllLetters);
}
result.ResultDictionary = frequencyDictionary;
return result;
}
The frequencies for each letter, calculated only from the words, can be seen in the following table:
| Letter | Letter Word Based Frequency |
|---|---|
| а | 12.59% |
| е | 9.02% |
| и | 8.95% |
| о | 7.67% |
| р | 7.34% |
| н | 6.64% |
| т | 5.42% |
| с | 5.2% |
| к | 4.58% |
| л | 4.02% |
| в | 3.96% |
| п | 3.72% |
| у | 3.08% |
| д | 2.69% |
| м | 2.38% |
| з | 2.17% |
| б | 1.64% |
| ч | 1.59% |
| г | 1.42% |
| ц | 1.22% |
| ј | 1.2% |
| ш | 1.1% |
| ж | 0.58% |
| ф | 0.57% |
| њ | 0.56% |
| х | 0.26% |
| џ | 0.15% |
| ќ | 0.12% |
| ѓ | 0.08% |
| љ | 0.06% |
| ѕ | 0.05% |
Sharing Data and Ideas
Now, the best thing to come out of this exploration is the email communication I had with the creator and the current developer/person responsible for the online dictionary I scrapped.
He mentioned that the frequencies calculated from only words are relatively incorrect as the word usage in the language also varies. The way I did the calculation is also against the initial frequency calculation for English Scrabble that was done based on New York Times front pages. So it makes sense for the calculation to be based on actual word usage, text, books and so on.
So, the developer was awesome enough to send me frequencies calculated from about ~55MB or plaintext Macedonian novels.
The frequencies calculated from the text are in the table below:
| Letter | Text Corpus Based Frequency (contributed - see end of post) |
|---|---|
| а | 13.66 % |
| о | 10.63 % |
| е | 9.91 % |
| и | 8.32 % |
| т | 7.06 % |
| н | 6.47 % |
| с | 4.79 % |
| р | 4.37 % |
| в | 4.27 % |
| д | 3.95 % |
| к | 3.82 % |
| м | 2.93 % |
| л | 2.88 % |
| п | 2.64 % |
| у | 2.38 % |
| г | 1.9 % |
| з | 1.72 % |
| ј | 1.67 % |
| ш | 1.6 % |
| б | 1.54 % |
| ч | 1.04 % |
| ц | 0.62 % |
| ж | 0.58 % |
| ќ | 0.41 % |
| њ | 0.28 % |
| ф | 0.24 % |
| х | 0.12 % |
| ѓ | 0.12 % |
| џ | 0.04 % |
| љ | 0.03 % |
| ѕ | 0.02 % |
As we can see there are some differences in the percentages and frequency ordering for some of the letters.
Conclusion
This entire exploration into letter frequencies in Macedonian was quite an adventure. I got to create and make use of a small scrapper that actually accomplished its goal fully and got all the data. I also had an interesting discussion regarding the different way to calculate the frequencies, either word or text.
I feel the text approach is realistically better for letter frequency usage. And as the initial English Scrabble tile sets where built on actual text usage it probably would be best to base Scrabble tile set based on the text frequencies.
Finally a comparison of the frequencies based on both text and words in one single table:
| Letter | Letter Word Based Frequency | Text Corpus Based Frequency (contributed - see end of post) |
|---|---|---|
| а | 12.59% | 13.66 % |
| е | 9.02% | 9.91 % |
| и | 8.95% | 8.32 % |
| о | 7.67% | 10.63 % |
| р | 7.34% | 4.37 % |
| н | 6.64% | 6.47 % |
| т | 5.42% | 7.06 % |
| с | 5.2% | 4.79 % |
| к | 4.58% | 3.82 % |
| л | 4.02% | 2.88 % |
| в | 3.96% | 4.27 % |
| п | 3.72% | 2.64 % |
| у | 3.08% | 2.38 % |
| д | 2.69% | 3.95 % |
| м | 2.38% | 2.93 % |
| з | 2.17% | 1.72 % |
| б | 1.64% | 1.54 % |
| ч | 1.59% | 1.04 % |
| г | 1.42% | 1.9 % |
| ц | 1.22% | 0.62 % |
| ј | 1.2% | 1.67 % |
| ш | 1.1% | 1.6 % |
| ж | 0.58% | 0.58 % |
| ф | 0.57% | 0.24 % |
| њ | 0.56% | 0.28 % |
| х | 0.26% | 0.12 % |
| џ | 0.15% | 0.04 % |
| ќ | 0.12% | 0.41 % |
| ѓ | 0.08% | 0.12 % |
| љ | 0.06% | 0.03 % |
| ѕ | 0.05% | 0.02 % |
Hope someone finds this useful and if people look for letter frequencies they can get to this article. That is actually why the categories (tag links) are both in Macedonian and English.
Big Thanks
A big thanks to the folks behind possibly the best digital Macedonian dictionary for all the work they have done to collect and display all the information about the words.
They also provided me with the information about the frequencies calculated from the text, which is awesome!
They can be found here and everyone should check out the work: