Recently I’ve had the chance to work with Dapper. It’s what’s called a Micro ORM framework for .NET, developed by Stack Exchange, famous mainly for Stack Overflow. And if you are reading this you are probably 99% familiar with the website :)
Dapper is said to be positioned very closely above ADO.NET classes and because of that it provides much faster operations.
One piece of the work I did with Dapper was inserting large amounts of data in a database. This post is going to look through 3 possible ways of doing the inserts with Dapper and present timed benchmarks for each of the approaches.

The post will mimic the way I did things initially and arrive somewhere at the end result of what is being used now to insert the large quantities of data.
NOTE: I want to mention that I’ve just started using Dapper recently and in a limited use case. I still have a lot to learn and I hope this post will be a good starting point and maybe be useful for someone else along the way!
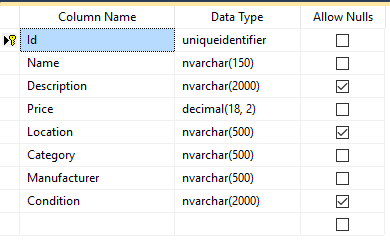
The schema and objects used for testing
We are using a very simple database schema for testing the inserts. We are starting off with a simple Products table that contains several columns. We are generating the data in C# using the Faker library/nuget package
The code used to generate the required collection for testing is quite simple:
using System;
using System.Collections.Generic;
using Dapper.BulkInserts.Dtos;
using Faker;
namespace Dapper.BulkInserts.TestData
{
public static class TestDataGenerator
{
public static Product GetProduct()
{
var product = new Product()
{
Id = Guid.NewGuid(),
Category = StringFaker.Alpha(10),
Condition = TextFaker.Sentences(4),
Description = TextFaker.Sentences(7),
Name = StringFaker.Alpha(40),
Location = LocationFaker.City(),
Manufacturer = StringFaker.Alpha(25),
Price = NumberFaker.Number(1, 500)
};
return product;
}
public static List<Product> GetProductCollection(int count)
{
var products = new List<Product>();
for (int i = 0; i < count; i++)
{
products.Add(GetProduct());
}
return products;
}
}
}
Because Dapper still performs certain object mapping functionalities, we can see above in the code we have a Product DTO with properties that reflect the table in the database.
This DTO will be used to perform all our inserts.
using System;
namespace Dapper.BulkInserts.Dtos
{
public class Product
{
public Guid Id { get; set; }
public string Name { get; set; }
public string Description { get; set; }
public decimal Price { get; set; }
public string Location { get; set; }
public string Category { get; set; }
public string Manufacturer { get; set; }
public string Condition { get; set; }
}
}
The benchmark aproach
I’d like to mention something about how the benchmarking is structured: I’ve setup a small program that can accept how much data to insert and how many times that data will be inserted using each of the approaches.
The data, the collection of products, are generated only once, and then used for each set of inserts using the 3 different methods.
After each insert, and at the end of the set run as well as the beginning, the database is cleared. When the next set starts the database is empty. I will not go into how this is organized in the code, but it can be seen in the source which I’ve linked at the end of the post.
NOTE: The database is cleared using Dapper. I will not get into how it’s done but you can see for yourselfs in the code located on Github, linked at the end of the post.
Dapper Functionality
Dapper from what I’ve seen so far offers extensions on the SqlConnection object from ADO.NET, which can be used to perform queries and execute commands but in a typed sort of way, by using objects/DTOs (hence the simple/micro ORM descriptor). The best way to maybe explain this is take a look at the very simple command used to insert a single record in the database table:
public void WriteSingleProduct(Product product)
{
using (var connection =
new SqlConnection(ConfigurationManager
.ConnectionStrings["ProductDapperDb"]
.ConnectionString))
{
connection.Execute(Commands.WriteOne, product);
}
}
We see that we are using an Execute method that takes in a SQL Command and the Product object. The WriteOne command is stored in a resource file. It’s a basic parameter insert query which is processed by Dapper, alongside with the product object and all the parameters on the query are populated by the object property values, based on matching property names with parameter names.
We can see that the SQL Query Write One defines parameters using ‘@’ which reflect the names of the product objects properties we are passing into the Execute:
INSERT INTO [dbo].[Products]
([Id]
,[Name]
,[Description]
,[Price]
,[Location]
,[Category]
,[Manufacturer]
,[Condition])
VALUES
(@Id
,@Name
,@Description
,@Price
,@Location
,@Category
,@Manufacturer
,@Condition)
This is one extend of the ORM that is done by Dapper. Looking at the Names of the SQL Parameters and mapping them to the names of the properties on Product.
Dapper Execute
Above and in the rest of the post we will be looking at a single extension method by Dapper on the Sql Connection object. The Execute method has the following general signature as taken from the Dapper Docs on Github:
public static int Execute(this IDbConnection cnn,
string sql,
object param = null,
SqlTransaction transaction = null)
The version used in the benchmark tests has some more parameters, which does not matter for the purposes of the test. I think the docs are a bit outdated there. Which is just one more reason to install Dapper with Nuget and go exploring yourself!
Either way, the interesting part is the param parameter which we will see can be utilized in very different ways.
Three Aproaches for the Same Thing!
After taking a look at the most basic way to insert a single record we are going to look at how we can leverage the approach to insert a collection of data in 3 different ways.
All of these methods are implemented using a ProductWriter data access abstraction class and it can be explored in the code for the benchmark linked at the bottom of this post.
Using a single insert with a for loop.
The most basic way and the first thing that came to mind when I was met with the task is similar to what we already actually saw before. We can very easily repeat the above command using a for/foreach loop and insert each Product in that way. That is exactly what the first benchmark test does.
private TimeSpan InsertUsingForLoop()
{
var stopwatch = Stopwatch.StartNew();
productWriter.WriteProductsWithExecuteForEach(product);
stopwatch.Stop();
return stopwatch.Elapsed;
}
We basically call an Execute for each of the products. That is done in the WriteProductsWithExecuteForEach method.
public void WriteProductsWithExecuteForEach(List<Product> products)
{
using (var connection = new SqlConnection(ConfigurationManager.ConnectionStrings["ProductDapperDb"].ConnectionString))
{
foreach (var product in products)
{
connection.Execute(Commands.WriteOne, product);
}
}
}
Here we are only utilizing the sql and param parameters on the execute method, setting param to a single product object.
Dapper runs an internal logic, and using reflection matches the property names to the parameter names in the sql query string. It then, runs and executes the statement on the database using the sql connection.
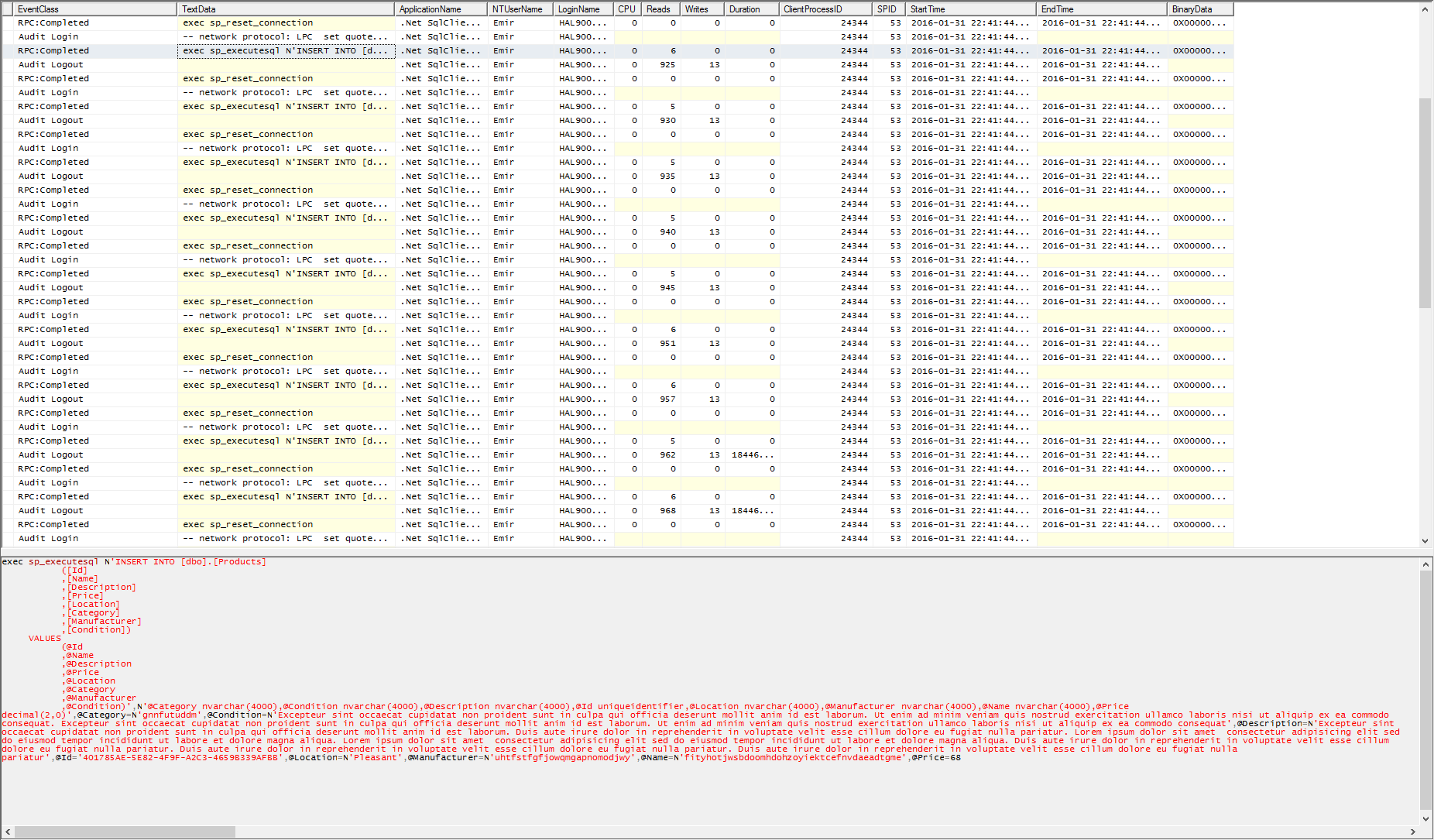
Right of the start this has the massive overhead of reseting a connection from the connection pool with the sp_reset_connection procedure before using it for each insert. You can read a little bit more about sp_reset_connection in the Benchmark Summary section that is yet to come! Be patient!
Although as a sneak peek we can see how this all looks in a SQL Profiler Trace:
Using an Execute implementation with a collection
This is where things start to get interesting. The beauty of the Execute extension method is that we can basically send everything as a param. This next insert method utilizes this and we are actually sending the entire collection of products as the parameter.
public void WriteProductCollection(List<Product> products)
{
using (var connection = new SqlConnection(ConfigurationManager.ConnectionStrings["ProductDapperDb"].ConnectionString))
{
connection.Execute(Commands.WriteOne, products);
}
}
At this point Dapper most probably runs some internal logic to figure out that it’s actually a collection of objects. It then inserts those objects by performing the SQL Query Property/Parameter matching process for each one.
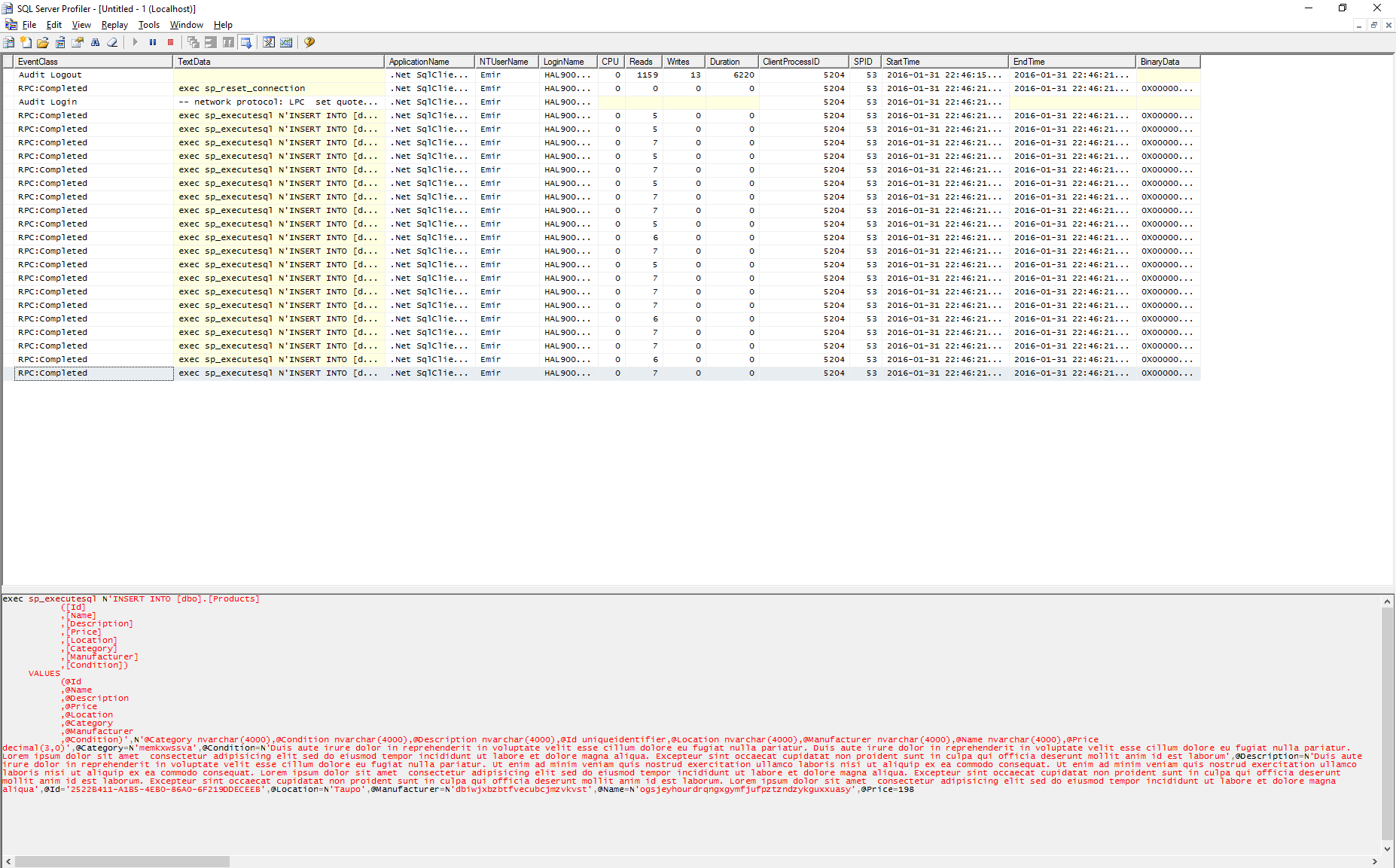
The difference here with versus running the single Execute multiple times is that internally Dapper inserts all the products but with a single sp_reset_connection call.
If we look at the profiling data we see that initial sp_reset_connection. Though, we still see a collection of inserts but let’s wait to see how this affects the results a bit later on
Using an Execute implementation and passing a data table parameter
The final approach we are going to look at is inserting bulk amounts of data using a Data Table parameter.
For this approach we need to define a Table Type in the database that reflects the properties we want to insert for the Product table:
CREATE TYPE [dbo].[ProductType] AS TABLE(
[Id] [uniqueidentifier] NOT NULL,
[Name] [nvarchar](150) NOT NULL,
[Description] [nvarchar](2000) NULL,
[Price] [decimal](18, 2) NOT NULL,
[Location] [nvarchar](500) NULL,
[Category] [nvarchar](500) NOT NULL,
[Manufacturer] [nvarchar](500) NOT NULL,
[Condition] [nvarchar](2000) NULL
)
We can now use a different approach in writing the query that is executed to insert the data. We can define a parameter that using Dapper will be set to a Data Table. Waaait for it!
INSERT INTO dbo.Products
SELECT * FROM @data;
We see that this query is very simple. It is using the INSERT INTO SELECT SQL Syntax. What is important is how the @data parameter is built and provided using Dapper. Let’s take a look at that next:
public void WriteProductCollectionUsingDataTable(List<Product> products)
{
using (var connection = new SqlConnection(ConfigurationManager.ConnectionStrings["ProductDapperDb"].ConnectionString))
{
DataTable dataTable = GetDataTableForProducts(products);
connection.Execute(Commands.BatchInsert,
new { @data = dataTable.AsTableValuedParameter("dbo.ProductType")});
}
}
Here we can see that we are executing Commands.BatchInsert which is just the INSERT INTO SELECT Query we saw above. We set the @data parameter to a Table Value Parameter which is created from the DataTable we build using the GetDataTableForProducts method.
The GetDataTableForProducts method uses a simple approach to build the DataTable. The implementation we are going to see uses a Nuget Library called FastMember which provides some Reflection utilities used to build the Data Table.
private DataTable GetDataTableForProducts(List<Product> products)
{
DataTable table = new DataTable();
using (var reader = ObjectReader.Create(products))
{
table.Load(reader);
}
table.SetColumnsOrder(
"Id",
"Name",
"Description",
"Price",
"Location",
"Category",
"Manufacturer",
"Condition"
);
return table;
}
The SetColumnsOrder is an extension method for DataTable that orders how the columns are organized. The reason it is used is because I had an issue in the case of having the order of properties on the Product class different than the order of properties as defined in the Table Type in SQL.
public static class DataTableExtensions
{
public static void SetColumnsOrder(
this DataTable table,
params String[] columnNames)
{
int columnIndex = 0;
foreach (var columnName in columnNames)
{
table.Columns[columnName].SetOrdinal(columnIndex);
columnIndex++;
}
}
}
Before looking at the results let’s take a look how the final Data Table Parameter method of inserts behaves when looking at a trace from SQL Profiler.

The profiler trace above is from a single benchmark run inserting 5 products at a time. The reason is so we can clearly see that only one command is run against the server and all the products and their values are defined and set in this single SQL Command.
We can now move on to the benchmark results!
Benchmark Results
The Benchmark Run we will be looking at is 10 runs each inserting a collection of 50000 Products on each run with each of the 3 different approaches.
Like it was mentioned previously the database is cleared between each run and between the data inserts in each run for each of the 3 methods.
The results can be seen below in the screenshot as well as in the table (just in case):
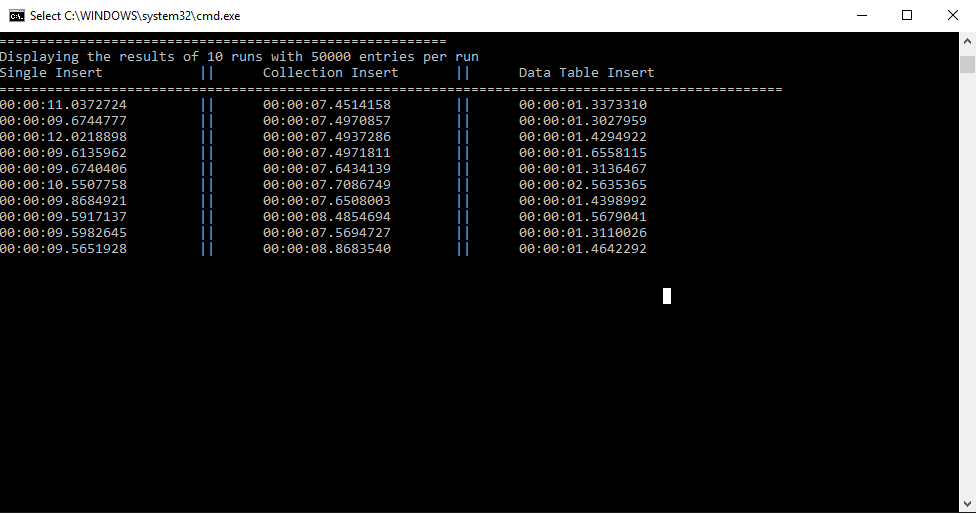
| Single Executes | Collection Execute | Table Value Parameter Execute |
|---|---|---|
| 00:00:11.0372724 | 00:00:07.4514158 | 00:00:01.3373310 |
| 00:00:09.6744777 | 00:00:07.4970857 | 00:00:01.3027959 |
| 00:00:12.0218898 | 00:00:07.4937286 | 00:00:01.4294922 |
| 00:00:09.6135962 | 00:00:07.4971811 | 00:00:01.6558115 |
| 00:00:09.6740406 | 00:00:07.6434139 | 00:00:01.3136467 |
| 00:00:10.5507758 | 00:00:07.7086749 | 00:00:02.5635365 |
| 00:00:09.8684921 | 00:00:07.6508003 | 00:00:01.4398992 |
| 00:00:09.5917137 | 00:00:08.4854694 | 00:00:01.5679041 |
| 00:00:09.5982645 | 00:00:07.5694727 | 00:00:01.3110026 |
| 00:00:09.5651928 | 00:00:08.8683540 | 00:00:01.4642292 |
We can clearly see, although maybe expected, that the fastest way in each of the runs is the 3rd approach, using Table Value Parameters. Additionally the difference in times is quite high!
The slowest way to do things is running an Execute for each of the objects which as we saw calls the sp_reset_connection procedure. We see that the middle aproach of using a single Execute is slightly faster, with the difference being the single sp_reset_connection call.
Doing a bit of research on sp_reset_connection I came across this Stack Overflow Answer which lists all the sub tasks performed by the stored procedure which explains the time differences.
At the end only one sp_reset_connection and a single Insert with all the necessary data to insert all the Products WINS!
Summary and Code
To summarize, the fastest approach (Table Type and Table Value Parameters) used to insert the products in this mocked case can be very easily refactored to be much more reusable. The only variable, besides the SQL script used to do the inserts is the method to create a Data Table from a collection. This can be refactored using a generic type parameter on the method.
Additionally the approach can be used and combined with different SQL statements, for example it can be used in combination with the MERGE statement to perform even more powerful operations.
Overall, Dapper is turning out to be a very enjoyable experience so far. I haven’t necessarily dug into it in detail yet, only performing simple reads and writes but so far I’m still excited to see what it has to offer.
I think I’ve spent waaaay too much time with Entity Framework and the simplicity, speed and minimalism is definitely refreshing.
Although I do think that it’s a whole different discussion if using Dapper is actually needed on all possible application use cases. It probably boils down to a whole bunch of different factors that need to be taken into consideration, but that is not the point of this post!
To learn more about Dapper and all it has to offer you can visit the official Github Repository
The Code
The code and examples can be found at the following repository. The code is a simple console application that initiates and runs a DapperBenchmark class, configurable with the number of runs and inserts per run.
The Commands.resx resource file contains all the SQL commands executed as well as the CreateFullSchema string that can be run to create the ProductDapperDb. Note that the Code expects an initialized database at localhost with the name ProductDapperDb. Note that CreateFullSchema is just an automaticly generated SQL Create Script from SSMS.